
Announcing DocParse storage: Cataloging, metadata extraction, and search for your parsed documents
March 24, 2025
You've used Aryn DocParse to process and provide structured output for your PDFs and other documents, but how do you now build the rest of your application? You could configure and use a variety of external tools for additional metadata extraction, search, and storage, but this sounds like a lot of work! Many of our customers spend significant effort building and managing their own systems to carry out these functions, and it only gets harder when you throw scale into the mix.
Now, it's easier than ever to build your document-based applications! We're excited to announce storage for DocParse, which enables you to automatically index, enrich, and search your parsed documents. It's built for scale, and you can store hundreds of thousands of documents.
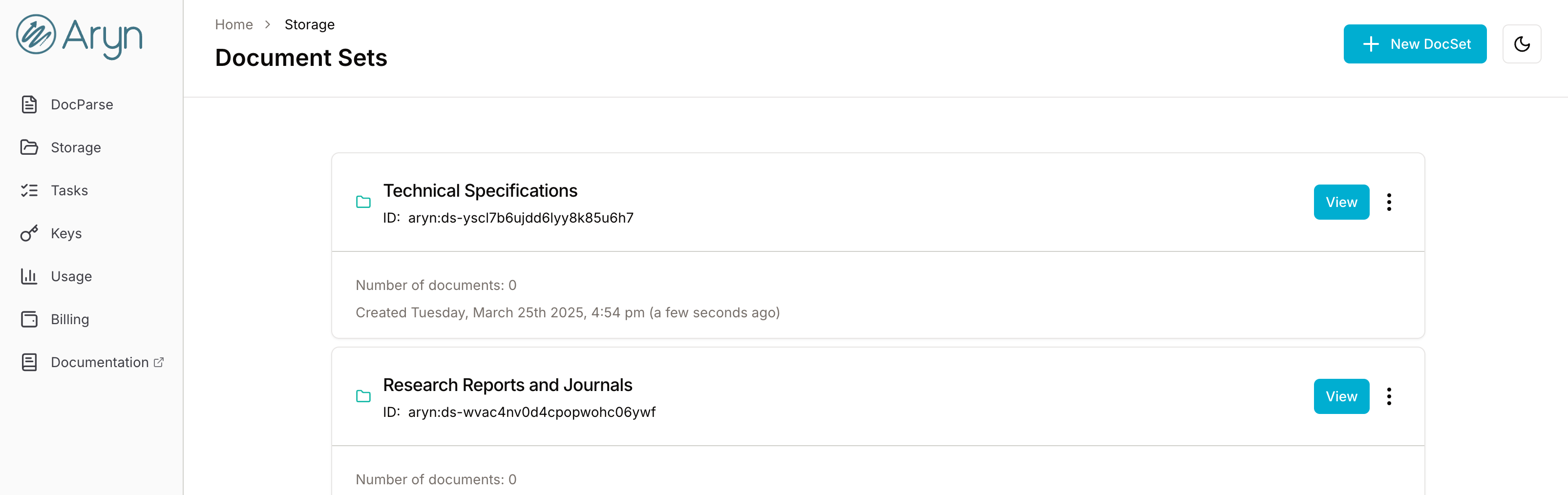
DocParse automatically adds your processed document to a Document Set (or DocSet), which is a collection of your documents that can scale to hundreds of thousands of docs. You can view the output of parsing, including bounding boxes for segmentation, extracted tables, image summaries, and more, in the Aryn DocParse UI. You can then use DocParse's GenAI-powered metadata extraction for document enrichment, and a search API to run vector and keyword search on your documents (and related metadata). This is all available via the DocParse UI and API (here is a notebook with Aryn SDK examples), so you can build your document processing and search applications on this storage layer. For more information on storage limits, visit the DocParse pricing page.
Let's dive a bit deeper into this new feature set!
Store and visualize the parsing of your documents
DocParse automatically stores your parsed document in a default DocSet named docparse_storage, and you can store up to 1k documents in the DocParse free tier (for information on storage limits, visit the Pricing Page). You can choose to create a new DocSet and specify DocParse to store your document there when using the DocParse UI or API. Furthermore, with a Pay As You Go plan, you can opt-out of storage.
Once you have parsed and stored your document, you can go to the DocParse storage page in the UI to view the parsed output. Click on your DocSet, and then the document to view.
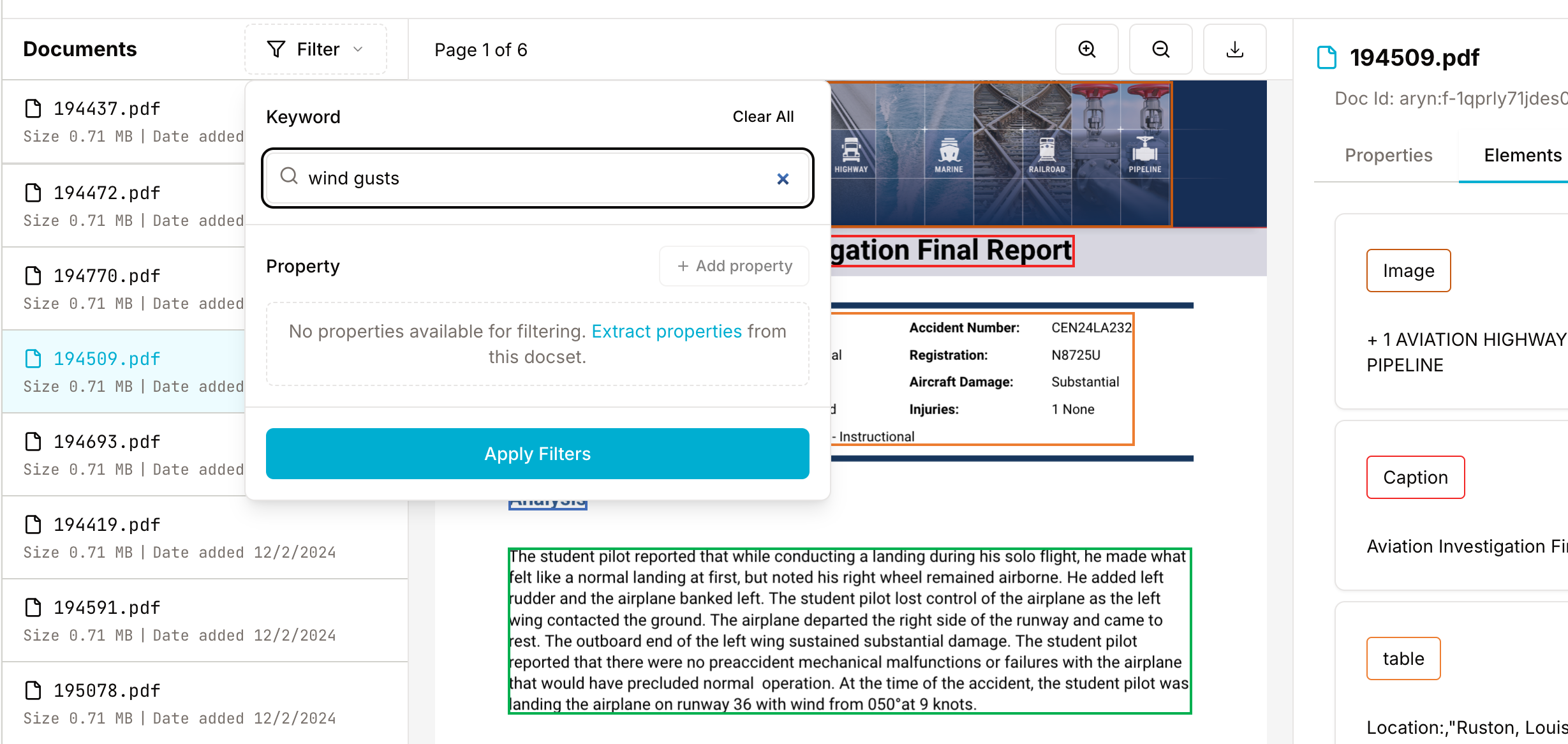
In the right-hand pane, you can view the metadata properties extracted from your document (by default, this will be empty - we'll show you how to extract properties using GenAI later in this post) or the elements (or chunks) of your document. Click on Elements. For each Element, you will see the labeled bounding boxes on your document and extracted contents. This makes it easy to inspect how DocParse processed your document.

Finally, you can use DocParse storage's Filters to select documents for further investigation. Click on the Filter button above the list of documents, and you can run a keyword search or filter documents by properties.
You can also do all of this using the Aryn SDK (notebook example).
Use GenAI-powered metadata extraction for enrichment
After parsing your document, extracting and storing additional document metadata can be important part of your document processing workload. Usage of this metadata can range from supplying structured data for an end-user app to enabling better quality search and retrieval on large collections of documents. DocStore storage makes it easy to extract metadata from the documents in your DocSet at scale using LLMs and store them as properties in your documents. Note that this feature is available only for accounts on the Pay As You Go plan.
Select your DocSet and go to the DocSet explorer page, and then click the Extract button on the top right. You can add up to 15 properties to extract at once from the UI, or up to 100 at once using the API. In this example, we'll extract the state where the incident happened, which is information contained in all of the reports. If the LLM cannot find a state name, DocParse will use the default value specified, which is an empty string.

Click Add Property, then Extract. This will start an asynchronous property extraction task, and you can view it by clicking the task ID link in the popup message or going to the Tasks page on the left navigation panel.
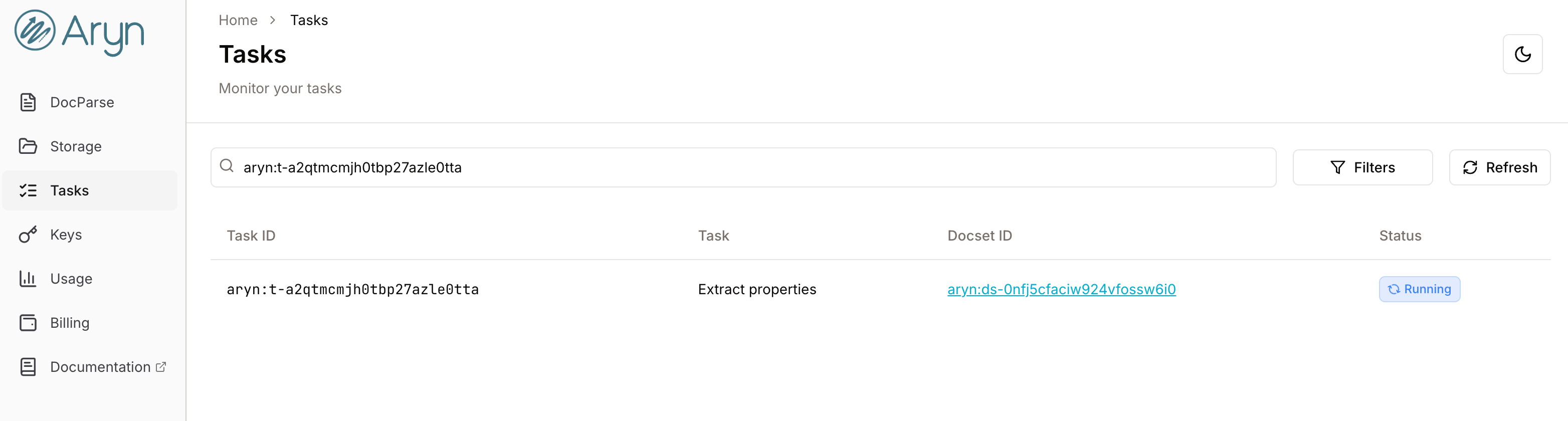
Once a Task is complete, it will be removed from the Task list after you refresh the page. Once the Extract Properties task is complete, you can see what was extracted for each document back in the Properties tab on right nav when selecting a document in the DocSet Explorer.
For an example on how to extract properties using the Aryn SDK, check out this notebook.
Properties are extracted on all the documents in your DocSet, and these properties will be extracted for every additional document added to the DocSet via DocParse.
Search your documents using keyword and vector search
Beyond filtering your document list in the DocSet Explorer, you can run full vector and keyword search on your parsed documents and associated properties in DocParse storage. This is currently available via the DocParse API, and a search UI is coming soon. The API makes it easy to integrate this search functionality with your application, from general enterprise search to RAG.
Searching your documents is fast an easy - here's a quick example using the Aryn SDK, where we will perform a vector search on the DocSet of airplane incident reports looking for "high wind speeds":
from aryn_sdk.client.client import Client, SearchQueryRequest
myClient = Client()
results = myClient.search(docset_id="YOUR-DOCSET-ID", query=SearchQueryRequest(query="high wind speeds", query_type="vector", return_type="element"))
The query_type supports vector and keyword search, and the return_type can return the indexed elements (created from parsing) or full documents that meet the search criteria. You can also add filters on document properties in your query request using the properties_filter parameter, and you can add complex filters with AND and OR statements. We will rerun the query above, but filter for incidents in the state of Texas:
from aryn_sdk.client.client import Client, SearchQueryRequest
myClient = Client()
results = myClient.search(docset_id="YOUR-DOCSET-ID", query=SearchQueryRequest(query="high wind speeds", properties_filter="(state='Texas')", query_type="vector", return_type="element"))
Build your document workflow applications with DocParse today
With our new storage and search functionality, you can now easily build applications and document workflow pipelines on the documents you process with DocParse. We'd love to hear your feedback - please contact us if you have any comments or questions. For more information about storage limits, visit the DocParse pricing page.